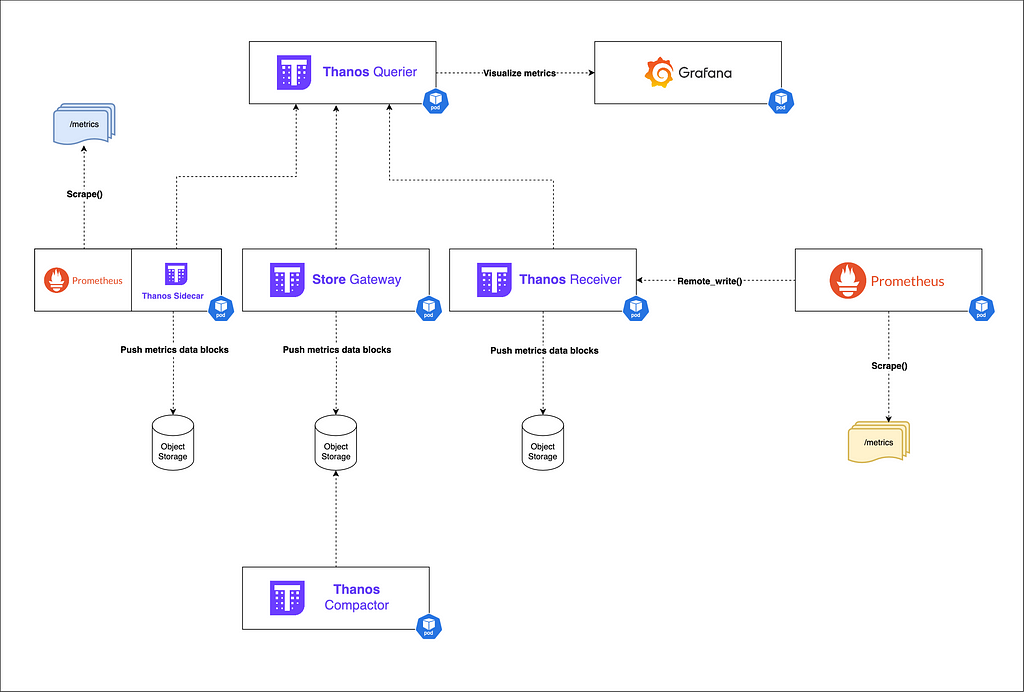
Observability 2.0: Breaking the Three-Pillar Silos for Good
Managing observability at scale has really changed with the rise of distributed systems, and the traditional three-pillar approach (metrics, logs, traces) has become one of the biggest bottlenecks …