
Before digging into any technical details, I will start with brief descriptions of the tools that I will be using for the tutorials (this part and the coming ones).
Cover Photo by Marius Masalar on Unsplash
1 — E(Elasticsearch).L(Logstash).K(Kibana) Stack !

The ELK Suite is an acronym for a combination of three widely used open source projects. E = Elasticsearch (inspired by Lucene), L = Logstash and K = Kibana. All developed in Java and published as Open Source under the Apache license. The addition of Beats turned the stack into a four-legged project and led to its renaming as “Elastic Stack”, but for us in this article we will at least use the official name of ELK.
- Elasticsearch is an open source, full-text search and analysis engine, based on the Apache Lucene search engine.
- Logstash is a log aggregator that collects data from various input sources, executes different transformations and enhancements and then ships the data to various supported output destinations.
- Kibana is a visualization layer that works on top of Elasticsearch, providing users with the ability to analyze and visualize the data.
The ELK stack is a super powerful combination that allows to perform high level and complicated aggregation, search and visualization on the top of large amounts of data indexed and stored in Elasticsearch.
2 — Apache Spark
Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Spark MLlib is a super useful library that allows a scalable and easy implementation of the common machine learning algorithms such as classification, regression, clustering and collaborative filtering in addition to other featurization algorithms and pipelines handling for models.
3 — ES-Hadoop
Elasticsearch for Apache Hadoop is an open-source, stand-alone, self-contained, small library that allows Hadoop jobs (whether using Map/Reduce or libraries built upon it such as Hive, or Pig or new upcoming libraries like Apache Spark ) to interact with Elasticsearch. One can think of it as a connector that allows data to flow bi-directionaly so that applications can leverage transparently the Elasticsearch engine capabilities to significantly enrich their capabilities and increase the performance.
Elasticsearch for Apache Hadoop offers first-class support for vanilla Map/Reduce, Pig and Hive so that using Elasticsearch is literally like using resources within the Hadoop cluster. As such, Elasticsearch for Apache Hadoop is a passive component, allowing Hadoop jobs to use it as a library and interact with Elasticsearch through Elasticsearch for Apache Hadoop APIs.
4 — Security for the stack
We always let the security til the end, which is not good since security is no longer an option, it should be considered from the whole beginning. Fortunately for us there is an option to secure our Elasticsearch Instance and plugins that interacts with it including ES-Hadoop.

Search Guard that’s an open source plugin for alerting and security for the elastic stack that comes with advanced security options to allow better integration in the various infrastructures that can be used with Elasticsearch.
Everyone loves Elasticsearch as software. Despite one very fundamental drawback it had in the beginning: No free security-related features whatsoever. Many vanilla Elasticsearch installations were wide open for attacks. Some still are today, leading to massive data breaches over time and we may not want that to happen to our data.
Security first and done right !
Sadly, we all know that security comes last in most software and infrastructure projects. Not providing any built-in security controls inevitably leads to data breaches and exposed data.
Provided as free Community Edition at no cost, licensed under Apache2, which covers all major security features required to run Elasticsearch in production safely:
- Mandatory TLS inter-node encryption
- REST layer TLS encryption
- HTTP Basic authentication
- Kibana access controls
- Role-based access control on index- and document type level
- Internal database of users, roles and permissions
- Alerting capabilities
The Community Edition offers a full feature set to mitigate almost all attack vectors, including ransomware attacks and data leakages. So there was no reason anymore to run an unsecured Elasticsearch cluster in production.
Now ! Let’s dig ‘securely’ into technical details.
Lets start the serious then and talk about the machine learning in Elasticsearch and how can we extend the capabilities of this powerful search engine. Elasticsearch OSS (open source version) doesn’t have yet any official machine learning integrations or capabilities and even the paid licensed ML by Elastic allow very few basic algorithms for anomaly detection and time series forecasting mainly. That’s pretty fair since Elasticsearch is a super powerful tool for indexing and search, and any addition feature would be good but what he already have is enough to make it super popular and widely adopted by companies and individuals. There are some existing plugins to add “learning” capabilities to Elasticsearch like elastiknn by Alex Klibisz that allows to run KNN classification in a pretty smooth and fast way, ML plugins from OpenDistro by AWS that allows KNN as well and probably Random forest very soon (according to their blog).
And there is the ES-Hadoop that allows to flow data between spark/hadoop and Elasticsearch so we can run all the available algorithms in SparkML directly on Elasticsearch without loosing the benefits of both🤓.
The Data I used for this article is the House Prices: Advanced Regression Techniques from kaggle, containing almost 79 variables that may affect the price of a house, and the goal is to perform data analysis techniques in order to understand the data and build house price predictive models.
Hands on
The first step is to load the data to elastic search to index it, and to do that we can either use Logstash to load the csv file from Kaggle directly, or we can use the upload option in Kibana ML tab.
- Ingesting the data using Logstash : After installing logstash, all we need to do is to create a configuration file where we tell logstash where to find the csv file and how to ingest it to Elasticsearch along with the index name and the credentials needed to login if we have any auth mechanism implemented using a security for elastic search plugin like SearchGuard, then run logstash with this configuration using the command :
| |
One thing to pay attention to while ingesting with Logstash to is the mappings 😬.Logstash will probably map all the variable to text/keyword and to avoid that I would recommend to insert a Json sample with the fields in the data set into a dummy indice and copy then edit the mapping of the main indice boston_houses. Or add a mutate option in the filter section in the conf file.
- Uploading the data with kibana
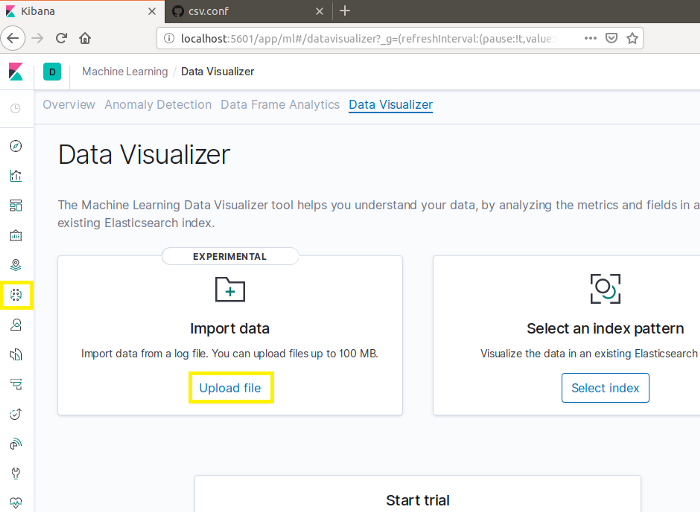
In the ML tab in Kibana UI we have an upload option that supports csv and log files to automatically index the data into Elasticsearch. This feature help us a little bit with our analysis since it does some super fast data and features description by default that we can use to delete probably some features where we have a lot of NaNs for example.
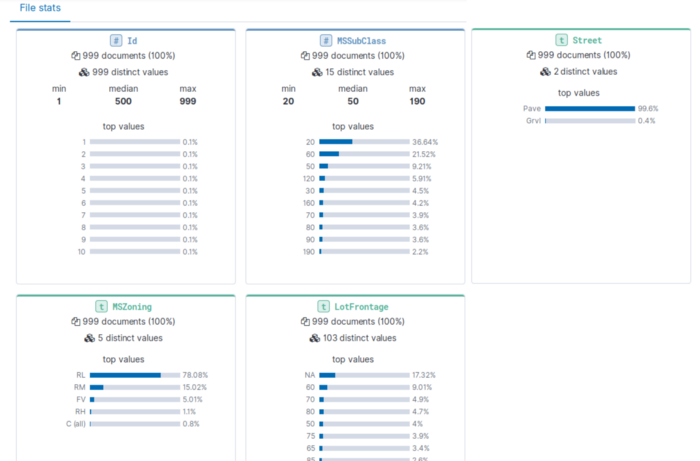
As we can see in the file stats, some variables may not be that helpful for our analysis and can be deleted without even performing any advanced correlation analysis. When the data is ingested and indexed in Elasticsearch, we should create an index pattern to be able to explore it .
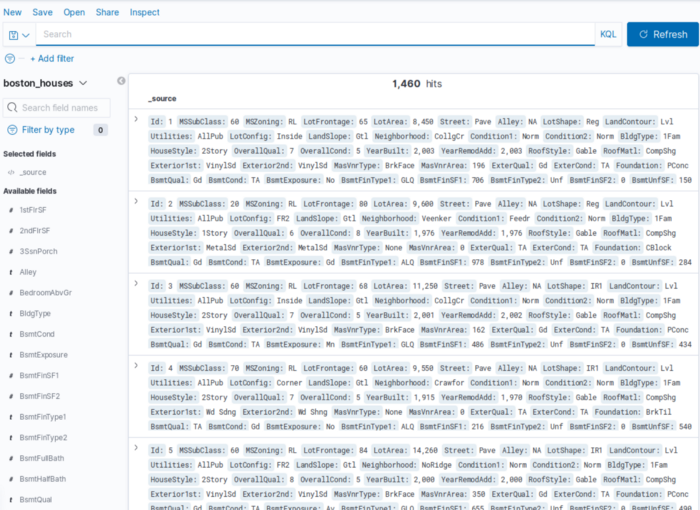
Visualization and analysis
After the data is successfully uploaded/imported to Kibana, we can do do lot of visualizations and statistical representations that probably will give us some insights .
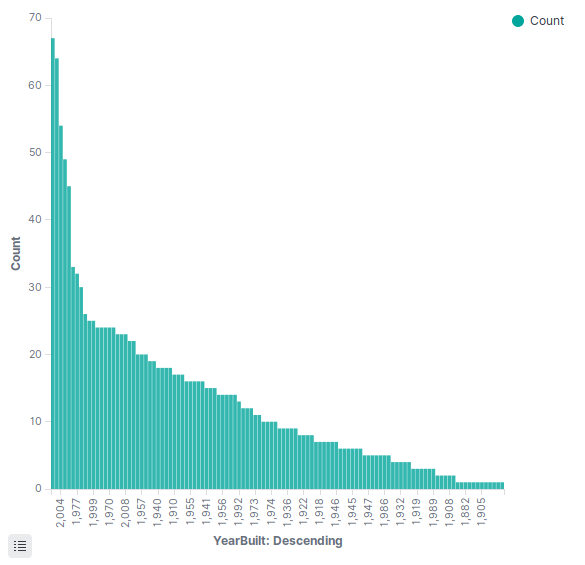
For example we notice that ‘recently’ built houses are sold the most, which is not surprising.
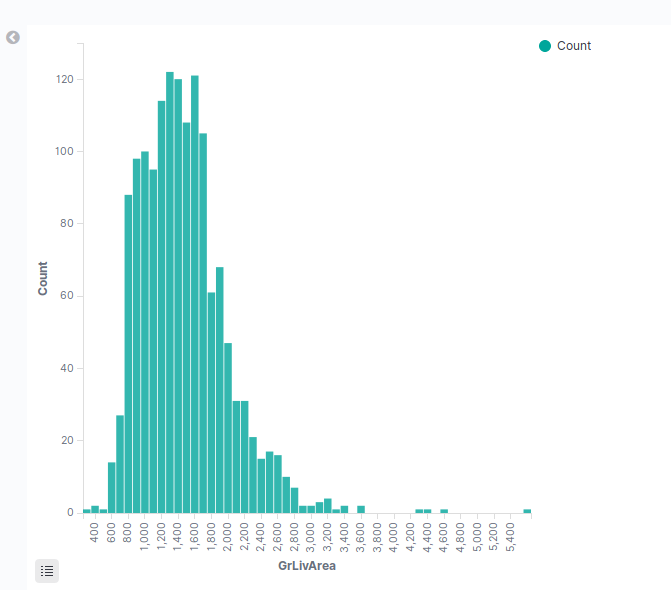
again we don’t see something strange, medium sized houses are sold the most.
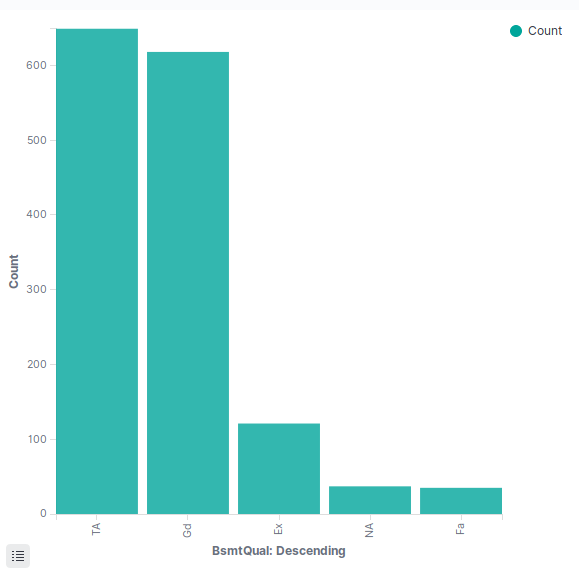
According to the data description the variable BsmtQual evaluates the height of the basement area, and we don’t see something special about that variable and we can make the hypotheses that it’s not really something that may affect the price of the house.
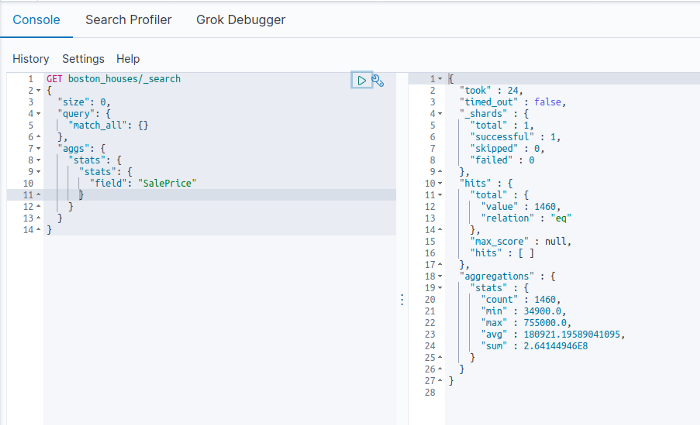
in addition to pretty visualizations Kibana allows also to execute queries and call Elasticsearch REST endpoints easily, that we can use to do lot of things including statistical queries and aggregations on the data in near real-time.
In terms of bivariate analysis, Kibana doesn’t allow that much of possibilities to visualize correlations but we can use the buckets and aggregations to try to get the max we can.
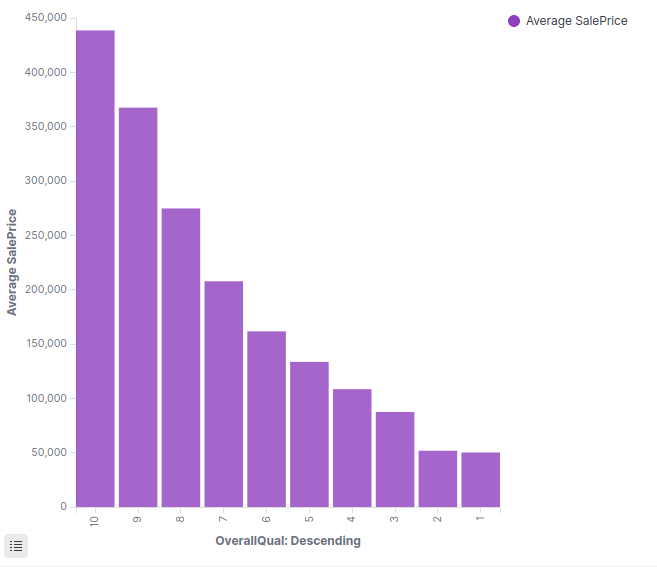
For example in the representation above we have the OverallQual that represents the building quality. And obviously the SalesPrice increases according to the quality and that’s a good sign ensuring that our data distribution is normal and doesn’t contain any strange behaviors.
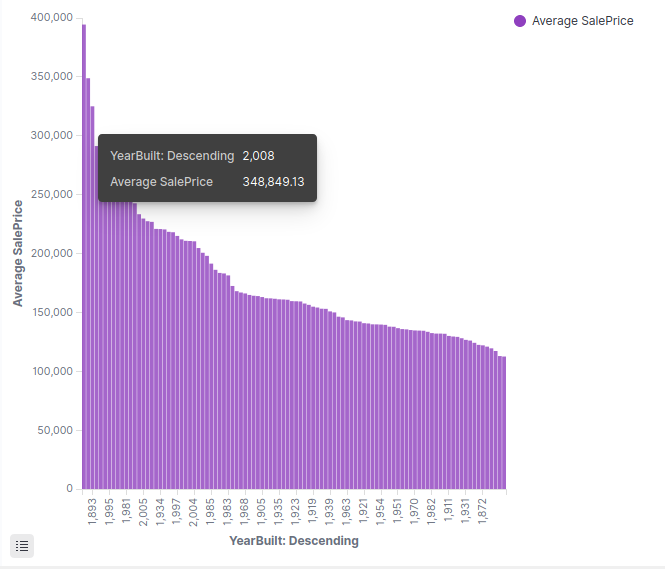
An other representation is YearBuilt that represents the year when houses are build and the prices. Again we don’t really see something strange since obviously people prefer ‘recently’ built houses.
Es-Hadoop & Spark
As we noticed above or as you are going to notice while playing with Kibana, in terms of correlation analysis Kibana is little bit limited. For that, elastic the company behind Elasticsearch have provided the Es-Hadoop (in their website known as Hadoop for Elasticsearch) that allows to merge and extend the capabilities of the most popular tools in the Apache family. Spark will add the real time analytics on the top of the real time search that Elasticsearch provides.
To interact with Elasticsearch, we have two options. We can run python files as Spark jobs or we can use Spark Shell and execute all our spells from there. Some examples of what we can do in terms of indexing can be found here.
- PySpark interpreter I used the command bellow to run PySpark interpreter with the elasticsearch-hadoop jar :
| |
NB : Spark doesn’t support java 11 yet, that’s means you need to download java 8 and edit your JAVA_HOME in order to run spark correctly.
The command to lunch the python script es-spark.py as a spark job :
| |
and in the file we can do all the reads/writes in Elasticsearch.
What’s next ?
The coming article will describe in details the following :
- Defining SearchGuard roles and users.
- Configure ES-Hadoop to securely read/write data using SearchGuard always.
- Run some regression algorithms and try to predict houses prices.
- Automatically predict prices for new entries in Elasticsearch.
Search Guard is a trademark of floragunn GmbH, registered in the U.S. and in other countries. Elasticsearch, Kibana, Logstash, and Beats are trademarks of Elasticsearch BV, registered in the U.S. and in other countries. Apache, Apache Lucene, Apache Hadoop, Hadoop, Spark, Kafka, HDFS and the yellow elephant logo are trademarks of the Apache Software Foundation in the United States and/or other countries. Open Distro for Elasticsearch is licensed under Apache 2.0. All other trademark holders rights are reserved