Getting Started With Terraform on AWS — State backend & State Locking
Getting Started With Terraform on AWS — State backend & State Locking

Getting started with Terraform is an exciting journey, but as the complexity of your infrastructure increases, so does the importance of managing its state. In the previous article , we installed Terraform, configured the aws provider and started using it. In this article, we’ll break down the crucial concepts of Terraform’s state backends and state locking, focusing on using the power of the S3 backend and DynamoDB for AWS environments.
1 — Terraform s3 state backend:
By default, Terraform stores its state file, terraform.tfstate, in the local filesystem and locks the state using system APIs . This approach is sufficient for Proof of Concepts (PoCs) and personal projects.
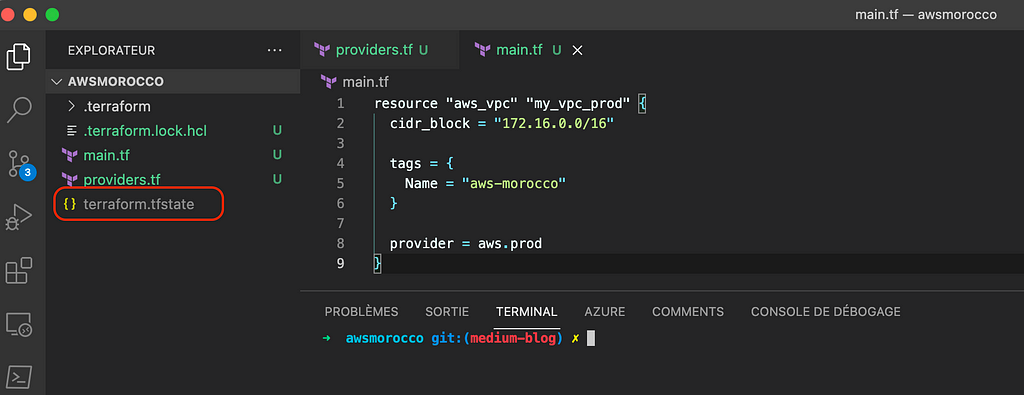
However, it becomes inadequate when multiple teams collaborate on the same Terraform project, making frequent additions or changes to resources and configurations. This scenario may involve different users, both human and programmatic, executing terraform apply. In such cases, maintaining a consistent and up-to-date state is critical, ensuring that each user accesses the most recent state file that accurately reflects the resources in AWS.
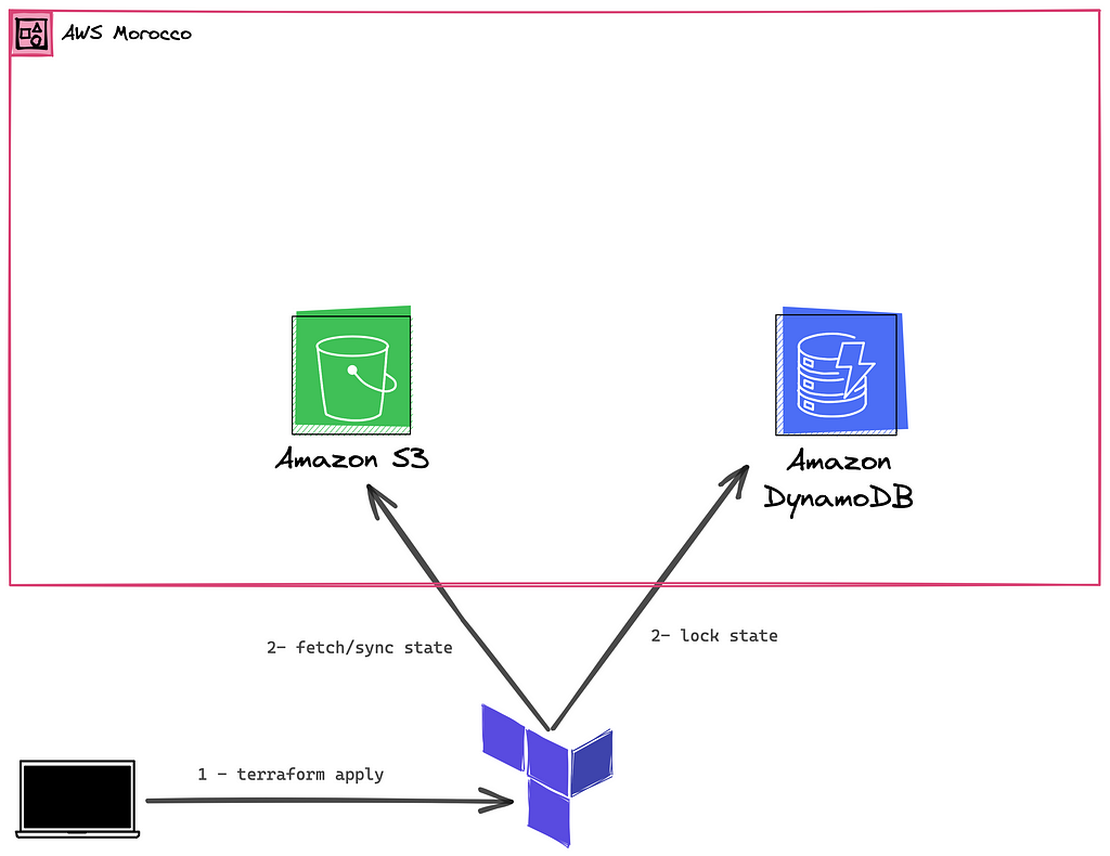
To address this need for collaboration and data consistency, Terraform offers a solution in the form of remote backends. One popular choice is the S3 backend, which allows you to store your state file in an Amazon S3 bucket. This offers several advantages, such as centralized state management, concurrent access for multiple users, and built-in versioning and locking mechanisms.
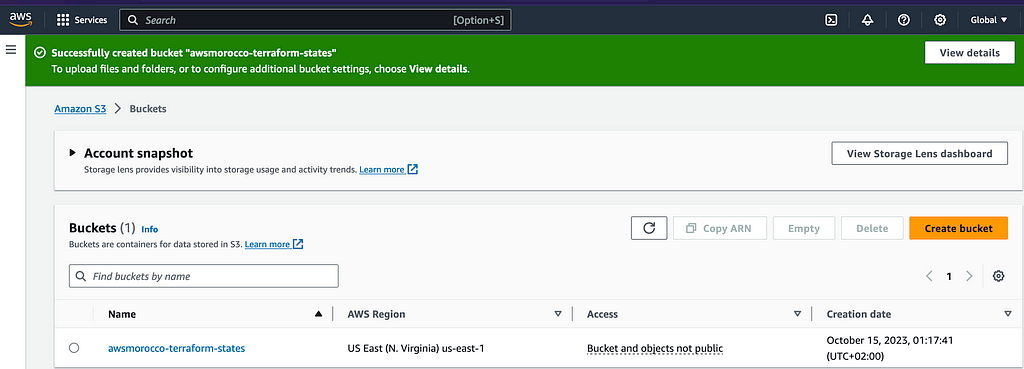
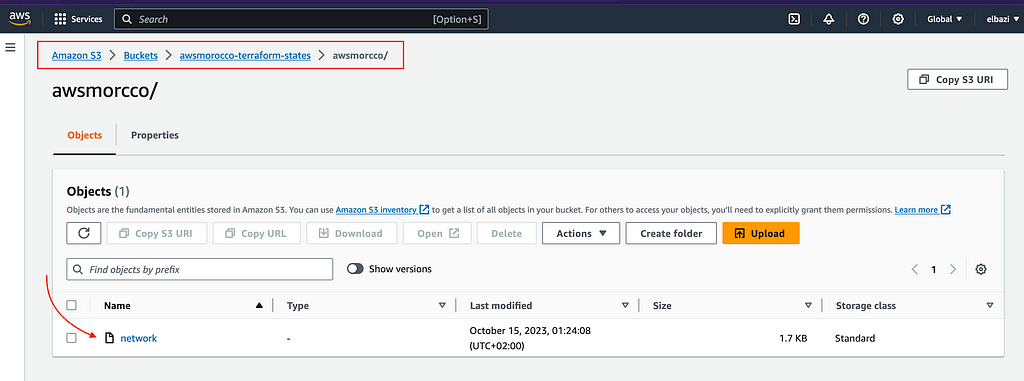
→ To set up the S3 backend, first, we need to create an S3 bucket (awsmorocco- terraform-states), preferably with bucket versioning enabled.
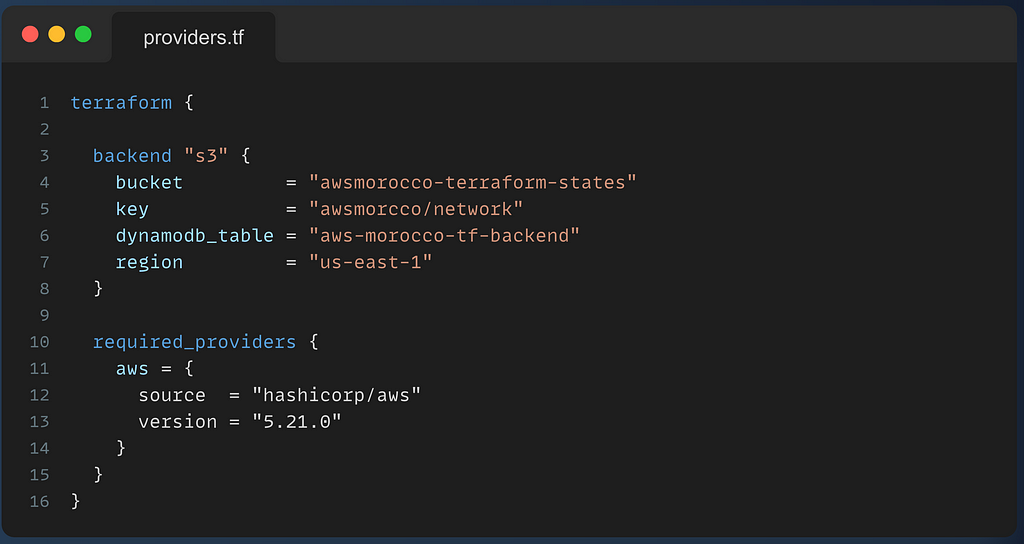
Then add the necessary configs in the terraform{} section in the providers.tf file.
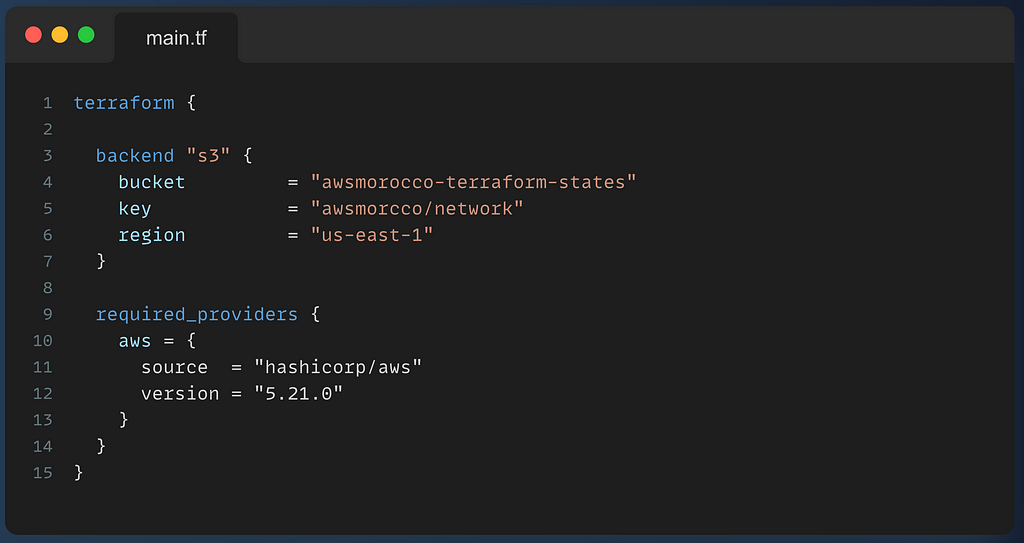
When we run terraform init && terraform apply, the state should be copied to the S3 bucket we specified, and any changes will be synced in S3.
2 — Terraform s3 state Locking
State locking is a crucial mechanism in Terraform to ensure data consistency and prevent conflicts when multiple users or automation processes are working on the same Terraform project.
It prevents simultaneous modifications of the state file (terraform.tfstate), which could lead to data corruption or inconsistencies. With state locking, only one user or process can make changes to the state at any given time, ensuring that all Terraform operations are coordinated effectively.
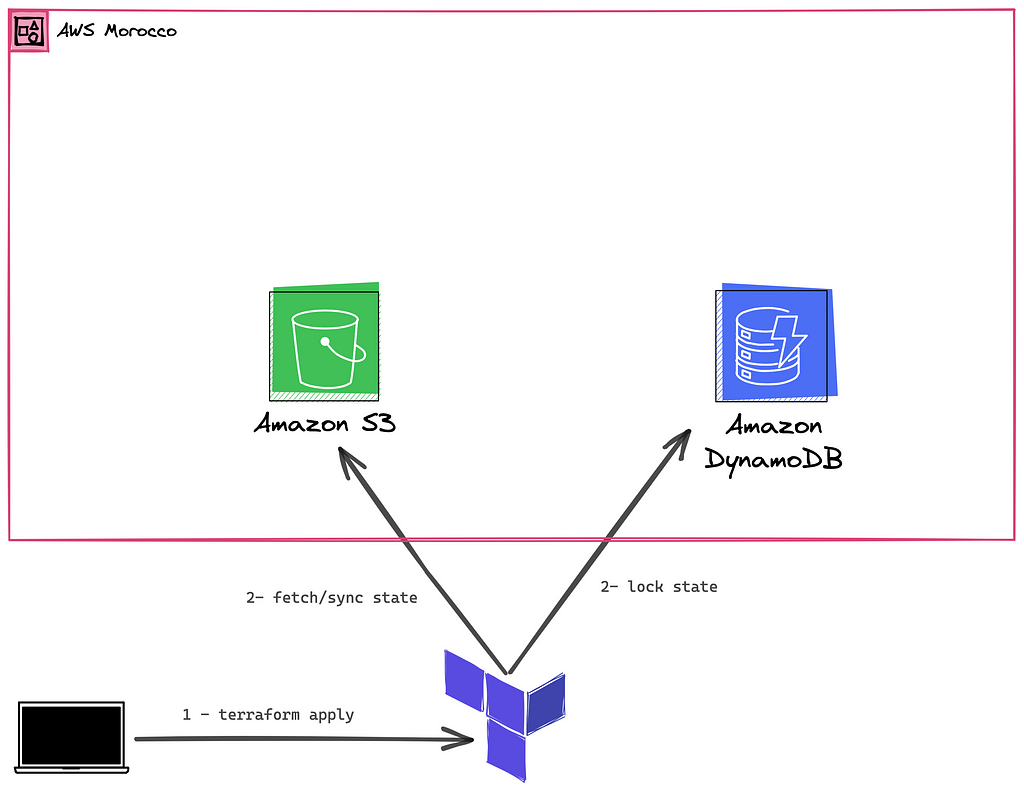
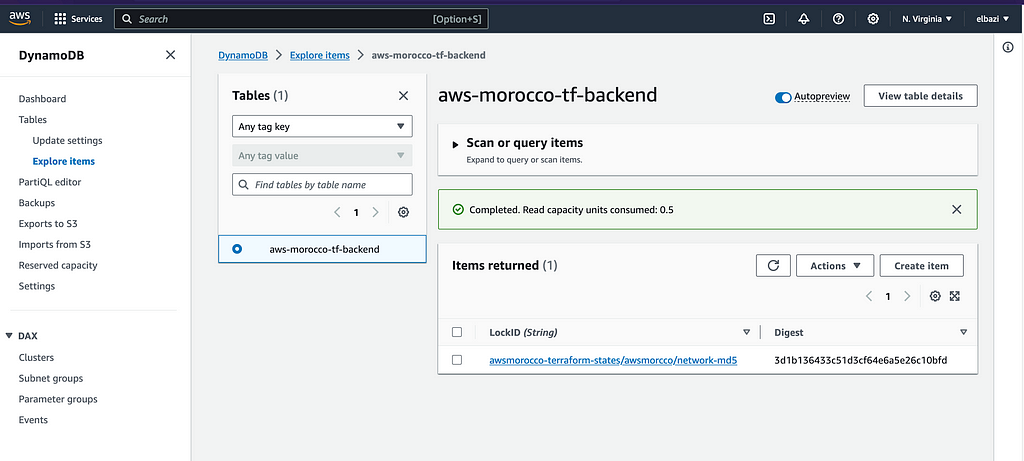
→ To implement state locking and prevent conflicts when using the S3 backend, Terraform allows you to configure a DynamoDB table to act as a locking mechanism.
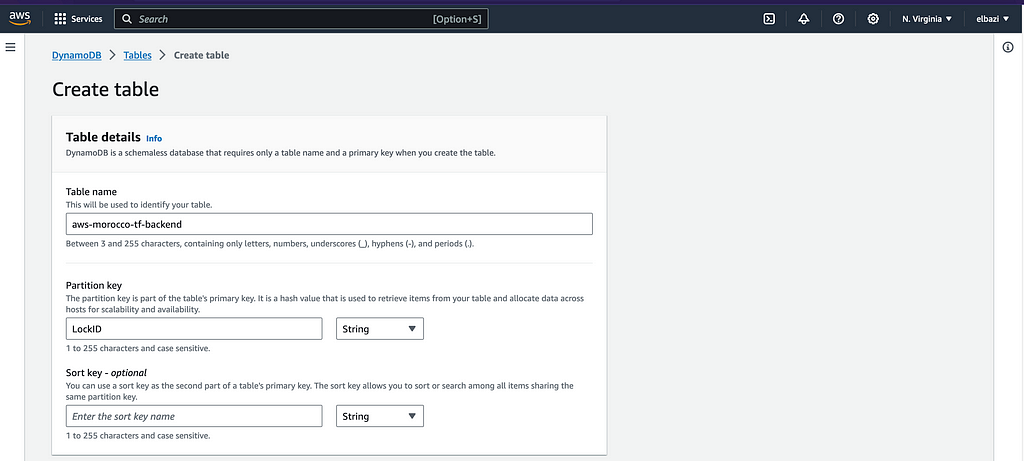
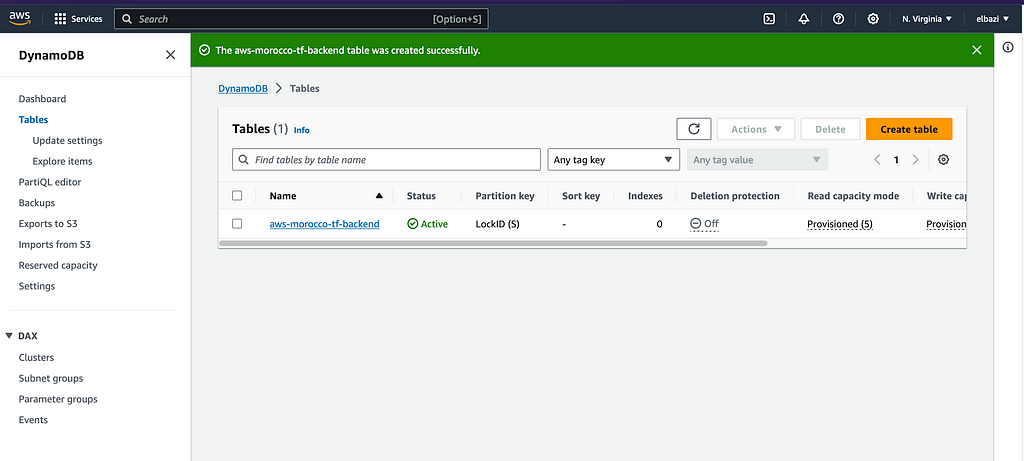
First, we need to create the DynamoDB table in the same region as the S3 backend bucket with a partition key (LockID) of type String.
Then, we add the necessary configurations about the state lock to the terraform{} config in providers.tf.
When you run terraform apply, Terraform will lock the state in the DynamoDB table until the apply is complete, and the state change is done.

3 — Conclusion:
When it comes to managing AWS infrastructure, mastering S3 state backends and Terraform state locking is a strategic imperative. The seamless integration of S3 backends, with their centralised storage and collaboration capabilities, ensures consistent and up-to-date Terraform state across multiple teams. Combined with DynamoDB state locking, data conflicts and inconsistencies are a thing of the past. As you navigate the Terraform AWS odyssey, the synergy of S3 backends and DynamoDB locking promises not only collaboration, but also enhanced infrastructure scalability.
—Read more:
- Backend Type: s3 | Terraform | HashiCorp Developer
- GitHub - Z4ck404/aws-morocco-samples: Aws morocco samples

[Getting Started With Terraform on AWS — State backend & State Locking](https://awsmorocco.com/getting-started-with-terraform-on-aws-state- backend-state-locking-eefd3ae98634) was originally published in AWS Morocco on Medium, where people are continuing the conversation by highlighting and responding to this story.
Disclaimer for Awsmorocco.com
The content, views, and opinions expressed on this blog, awsmorocco.com, are solely those of the authors and contributors and not those of Amazon Web Services (AWS) or its affiliates. This blog is independent and not officially endorsed by, associated with, or sponsored by Amazon Web Services or any of its affiliates.
All trademarks, service marks, trade names, trade dress, product names, and logos appearing on the blog are the property of their respective owners, including in some instances Amazon.com, Inc. or its affiliates. Amazon Web Services®, AWS®, and any related logos are trademarks or registered trademarks of Amazon.com, Inc. or its affiliates.
awsmorocco.com aims to provide informative and insightful commentary, news, and updates about Amazon Web Services and related technologies, tailored for the Moroccan community. However, readers should be aware that this content is not a substitute for direct, professional advice from AWS or a certified AWS professional.
We make every effort to provide timely and accurate information but make no claims, promises, or guarantees about the accuracy, completeness, or adequacy of the information contained in or linked to from this blog.
For official information, please refer to the official Amazon Web Services website or contact AWS directly.


