Do Pods Really Get Evicted Due to CPU Pressure?
- z4ck404
- Aws , Eks , Kubernetes
- March 21, 2024
As Kubernetes administrators and developers, we’ve all heard the notion that pods can get evicted due to high CPU pressure on a node. But is this really true? Let’s explore this idea and put it to the test.
1 — Understanding Pod Eviction and CPU Management
In Kubernetes, pod eviction is the process of removing one or more pods from a node in order to reclaim resources. This can happen for various reasons, such as:
- Node Failure : If a node becomes unreachable or unhealthy, the control plane will evict the pods running on that node.
- Node Maintenance : When a node needs to be drained for maintenance or upgrade purposes, the pods running on it will be evicted.
- Node Pressure : If a node runs out of critical resources like memory or storage, Kubernetes may evict one or more pods to reclaim those resources.
However, pods are not typically evicted directly due to high CPU pressure or usage alone. Instead, Kubernetes relies on CPU throttling mechanisms to manage and limit a pod’s CPU usage.
2 — CPU Requests and Limits
When you define CPU requests and limits for a pod, you’re specifying the minimum and maximum amount of CPU that the pod’s containers can use. The Kubernetes scheduler uses these values to determine where to schedule the pod and to ensure fair CPU sharing among pods on the same node.
3 — CPU Throttling
If a container tries to use more CPU than its specified limit, the Linux kernel’s CPU management mechanisms (like CPU shares or CPU quotas) will throttle or limit the container’s CPU usage to prevent it from monopolizing the node’s CPU resources. This throttling ensures that other containers on the same node can still receive their fair share of CPU.
4 — Indirect Eviction Due to Resource Pressure
While high CPU usage by a pod doesn’t directly lead to eviction, it can indirectly contribute to resource pressure on a node. If a pod’s CPU usage causes it to consume an excessive amount of memory, it may lead to the pod being evicted due to memory pressure on the node.
Additionally, the Kubernetes control plane monitors the resource usage of nodes and can mark a node as having insufficient resources if it consistently violates certain thresholds. This can cause the scheduler to stop scheduling new pods on that node and potentially evict existing pods to alleviate the resource pressure.
Testing CPU Throttling
1 — Deploying a CPU-intensive workload
To observe CPU throttling in action, we can deploy a CPU-intensive workload and monitor the pod’s CPU usage.
apiVersion: apps/v1
kind: Deployment
metadata:
name: cpu-stress-deployment
labels:
app: cpu-stress
spec:
replicas: 3
selector:
matchLabels:
app: cpu-stress
template:
metadata:
labels:
app: cpu-stress
spec:
automountServiceAccountToken: false
containers:
- name: stress-ng
image: litmuschaos/stress-ng:latest
resources:
requests:
memory: "200Mi" # Request 200 megabytes of memory
limits:
cpu: "100m" # Limit to 1/10 CPU
memory: "200Mi" # Limit to 200 megabytes of memory
args:
- "--cpu"
- "2" # Run 2 CPU stress workers
- "-t"
- "600s" # Run for 600 seconds (10 minutes)
- "--log-brief" # Output a brief summary of stressor activity
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: stress-ng
operator: In
values:
- enabled
- This YAML file defines a Kubernetes Deployment for running CPU stress tests using the stress-ng tool. It creates 3 replicas of a container named stress-ng based on the litmuschaos/stress-ng:latest image.
- Each container is configured with resource limits and requests for CPU and memory. The CPU limit is set to 1/10 of a CPU, and the memory limit is set to 200 megabytes.
- The container is configured to run 2 CPU stress workers for a duration of 600 seconds (10 minutes).
The Deployment is also configured with node affinity, requiring nodes with the label stress-ng set to enabled that was in t3.small instance for the tests.
2 — monitoring and observations:
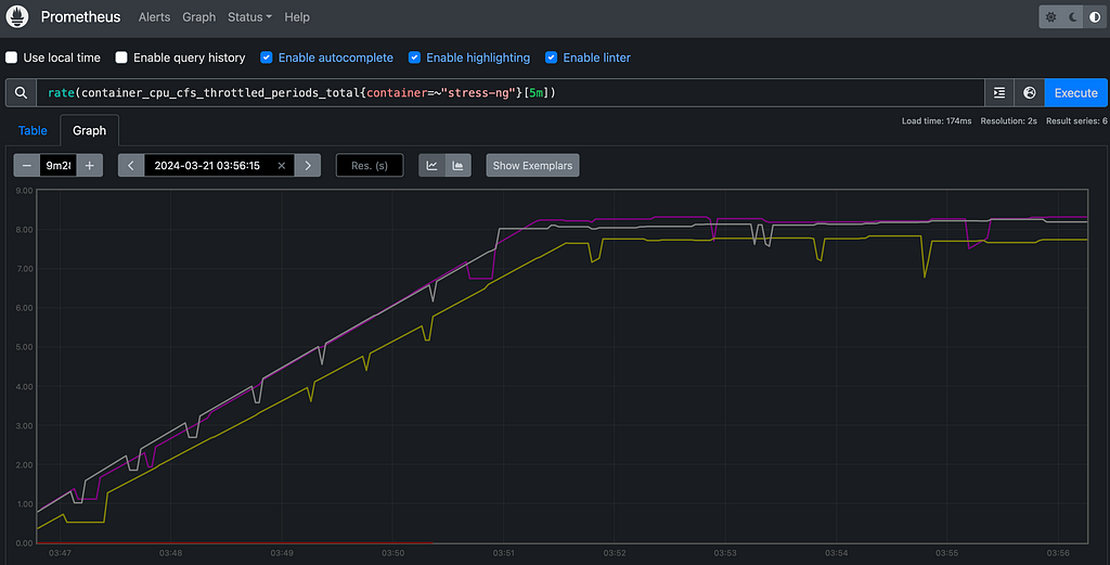
The container_cpu_cfs_throttled_periods_total metric shows the total number of periods that the CPU of a specific container has been throttled. The rate(container_cpu_cfs_throttled_periods_total{container=~“stress-ng”}[5m]) query calculates the per-second average rate of increase of the container_cpu_cfs_throttled_periods_total metric over the last 5 minutes for containers whose name matches the regular expression stress-ng.
 rate(container_cpu_cfs_throttled_periods_total{container=~”stress-
ng”}[5m])
rate(container_cpu_cfs_throttled_periods_total{container=~”stress-
ng”}[5m])
As we can observe the rate is around 7 means that the container has been throttled for an average of 7 periods per second over the last 5 minutes. Which also means that the container has been throttled for 700ms every second on average over the last 5 minutes.
The “period” is a length of time defined by the Linux Completely Fair Scheduler (CFS), which by default is 100ms.
An other query we can have a look at is rate(container_cpu_usage_seconds_total{container=~“stress-ng”}[5m]) which calculates the per-second average rate of increase of the container_cpu_usage_seconds_total metric over the last 5 minutes for containers whose name matches the regular expression stress-ng.
rate(container_cpu_usage_seconds_total{container=~”stress- ng”}[5m])
The rate is around 0.1 means that the container has been using 1/10 of a CPU on average over the last 5 minutes which represents the limit set for the container.
Conclusion
Through this exploration, we’ve learned that pods are not directly evicted due to high CPU pressure or usage alone. Instead, Kubernetes relies on CPU throttling mechanisms to manage and limit a pod’s CPU usage, ensuring fair resource sharing among pods on the same node.
While high CPU usage by a pod can indirectly contribute to resource pressure and potentially lead to eviction due to memory or other resource shortages, CPU throttling is the primary mechanism used to manage CPU-intensive workloads.

Do Pods Really Get Evicted Due to CPU Pressure? was originally published in AWS Morocco on Medium, where people are continuing the conversation by highlighting and responding to this story.
Disclaimer for Awsmorocco.com
The content, views, and opinions expressed on this blog, awsmorocco.com, are solely those of the authors and contributors and not those of Amazon Web Services (AWS) or its affiliates. This blog is independent and not officially endorsed by, associated with, or sponsored by Amazon Web Services or any of its affiliates.
All trademarks, service marks, trade names, trade dress, product names, and logos appearing on the blog are the property of their respective owners, including in some instances Amazon.com, Inc. or its affiliates. Amazon Web Services®, AWS®, and any related logos are trademarks or registered trademarks of Amazon.com, Inc. or its affiliates.
awsmorocco.com aims to provide informative and insightful commentary, news, and updates about Amazon Web Services and related technologies, tailored for the Moroccan community. However, readers should be aware that this content is not a substitute for direct, professional advice from AWS or a certified AWS professional.
We make every effort to provide timely and accurate information but make no claims, promises, or guarantees about the accuracy, completeness, or adequacy of the information contained in or linked to from this blog.
For official information, please refer to the official Amazon Web Services website or contact AWS directly.


